

分享两个Emmet使用中的技巧,可以简便快捷的批量修改大量代码,节省大量的人力和时间。
下面以工作中遇到的实例来说明。
1. 批量生成连续编号的并列元素

比如现在有上图这样的代码,需要制作同样的20行升序<li>。
即,从
<li><a href="_pdf/aichig01.pdf" target="_blank" class="pdf_size">関連図1</a></li>
到
<li><a href="_pdf/aichig20.pdf" target="_blank" class="pdf_size">関連図20</a></li>
那么,我们当然可以使用快捷键⌘+⇧+D (Mac)来把第一条<li>复制20遍,然后再一个一个去改数字。
然而那么做还是不够方便,我们可以使用以下的写法来批量生成指定数量的,并且是连续编号的相同元素。
li*20>a[_pdf/aichig$$.pdf target="_blank" class="pdf_size"]{関連図$}
这里批量生成层级元素就是正常的Emmet写法,重点是$代表的是数字,自动从1开始编号,如果需要前面补0的两位数的话就用$$,同理,三位数就用$$$。

写完后按一下TAB键就会得出以下的代码。
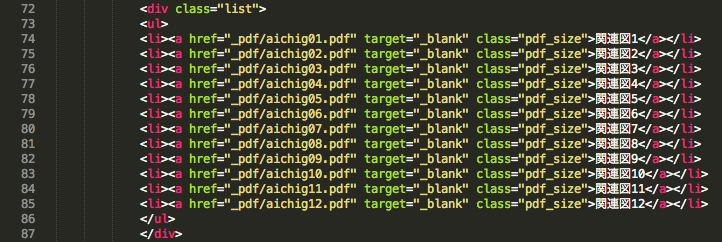
非常方便实用!!强力推荐!!
2. 批量置换含有不同内容的并列元素
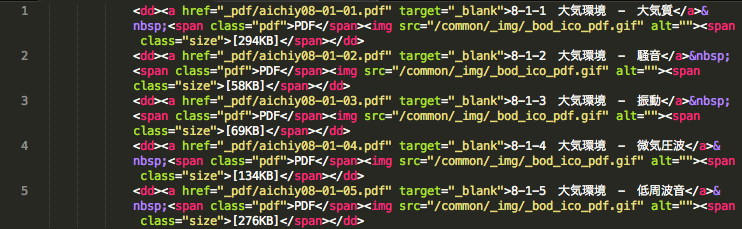
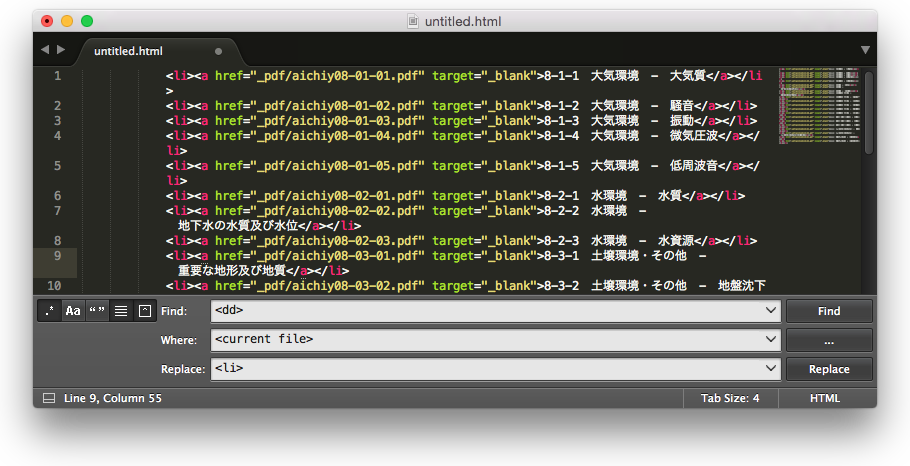
如上图这样的代码,我们需要将每行的dd改成li,并删除</a>后面的代码。
貌似挺简单的,dd改li使用检索置换就可以了,问题是</a>后面的代码里夹杂着不同的内容,比如第1行里有[294KB],第2行是[58KB]……,每行都不一样,传统的检索置换是没办法一次改掉的。
如果一行一行去删的话也太费时间精力了。
万幸,我们还有正则可以用!
按Ctrl+Shift+F (Windows)打开检索置换栏,在检索框里拷入以下代码:
<span class="pdf">PDF</span><img src="/common/_img/_bod_ico_pdf.gif" alt=""><span class="size">.*</span></dd>
就是复制</a>后面那一段,然后把内容改成.*,代表所有的内容,置换里写</li>。
如下图所示:
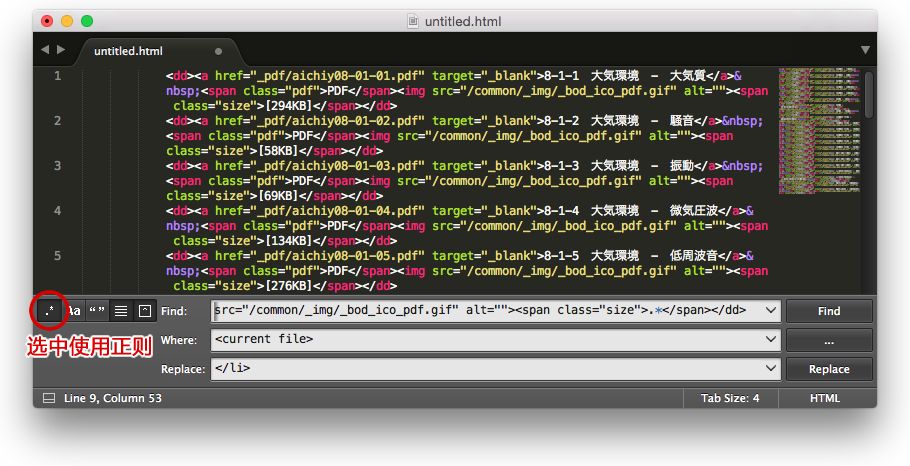
注意:检索栏最左边的按钮请点上!这样才是按正则来检索的,否则只会查找内容是.*的部分。
置换后得到以下结果。
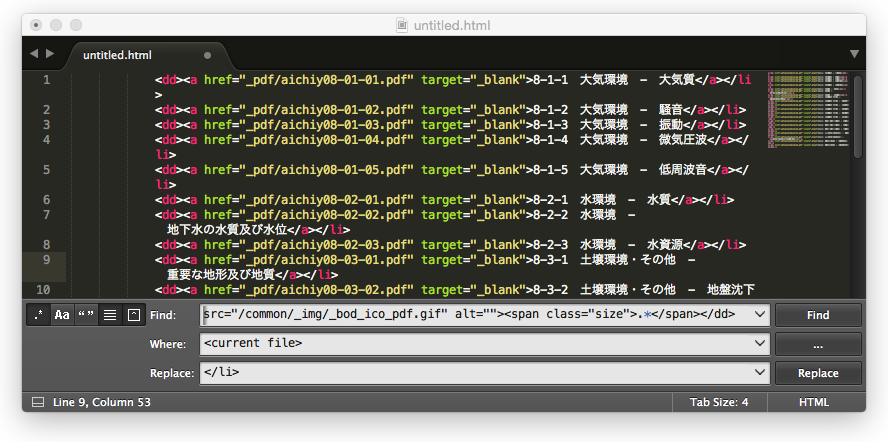
最后把<dd>置换成<li>就大功告成了!
实际工作中,有几百行代码需要这样置换,几秒钟就搞定了!嘻嘻(*^__^*)
但是如何只置换代码部分,而保留各自的内容,我还没有试出来,哪位大神知道的话还望不吝赐教。